Table of Contents
Open Table of Contents
- 1. Introduction
- 2. Architecture Overview
- 3. Decision Criteria
- 4. Backend Language: Python + FastAPI
- 5. Authentication: AWS Cognito
- 6. Database: DynamoDB
- 7. Messaging: SQS, EventBridge
- 8. Object Storage: S3
- 9. API: AWS HTTP API Gateway
- 10. Monitoring: CloudWatch Metrics, CloudWatch Logs + SNS, X-Ray
- 11. LocalStack
- 12. IaC: Terraform
- 13. React + Vite
- 14. Electron
- 15. Playwright
- 16. CI/CD: Local Bash Scripts + GitHub Actions
- 17. Next in the Series
- Series Navigation
1. Introduction
Part 1 covered the initial server-based architecture and requirements analysis. Part 2 discussed the cost crisis when AWS Free Tier ended and the decision to migrate to serverless architecture—primarily driven by cost optimisation for a low-traffic internal tool. This post examines the specific technology choices I made during the serverless migration and provides a detailed rationale for each decision.
2. Architecture Overview
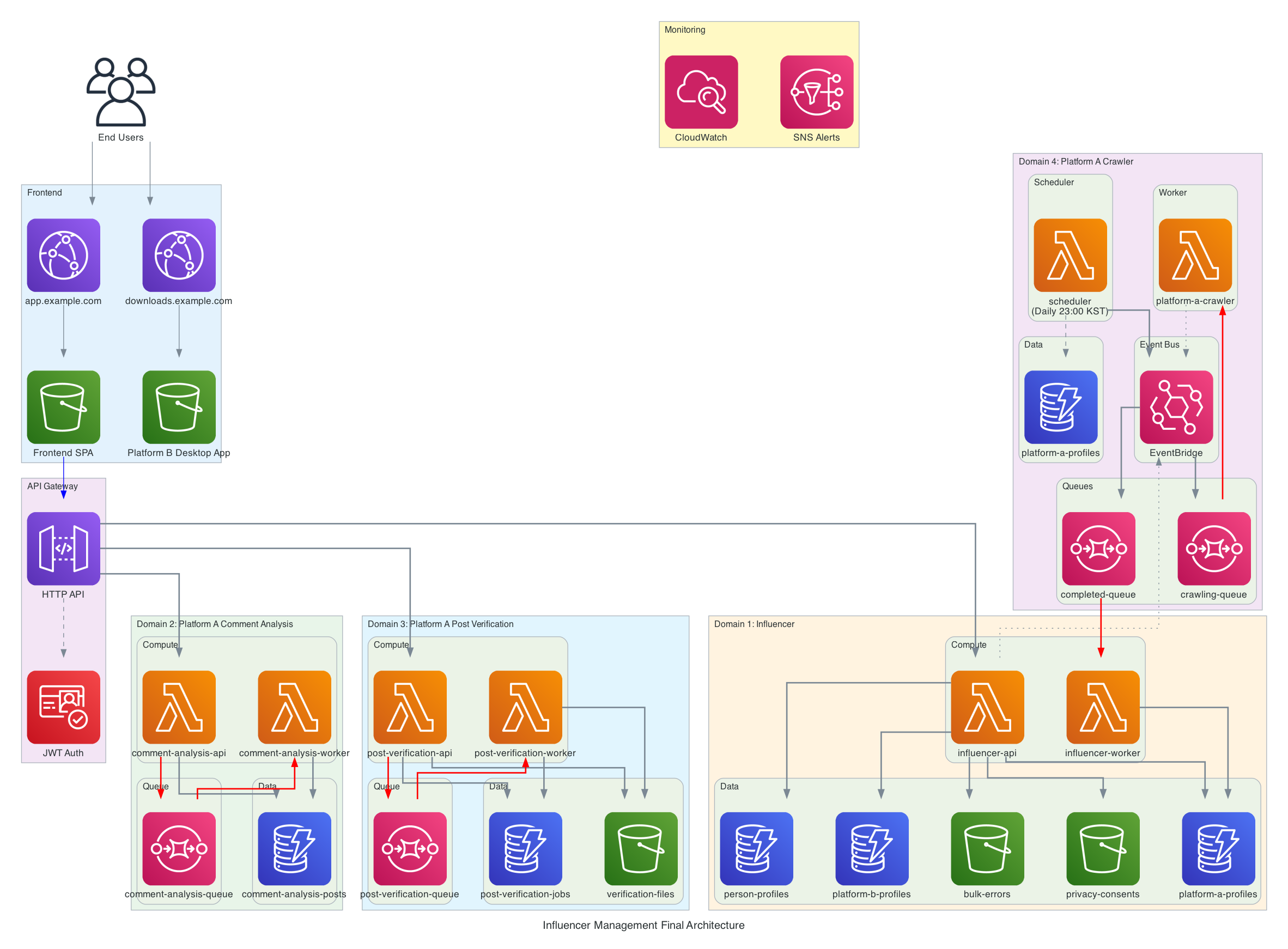
3. Decision Criteria
The primary motivation for migrating to a new architecture was cost optimisation; consequently, all technology choices prioritised cost efficiency. I particularly focused on AWS services offering an always-free tier. The secondary consideration was reducing operational overhead, and finally, I considered my own development productivity, as I wanted to complete the migration quickly.
4. Backend Language: Python + FastAPI
I chose Python as the primary backend language.
Previously, I had built the backend server using the TypeScript-based Nest.js framework.
One of the main reasons for switching to Python was its Excel file processing ecosystem.
The users of this platform rely heavily on Excel in their workflow. They frequently upload files in Excel format, download data as Excel files, or download error reports when bulk operations partially succeed.
When bulk influencer registration encounters validation errors, the system allows partial success. Valid entries are processed successfully, while failed entries are collected into an Excel file with an error reason column. The API returns a JSON response with summary statistics (total, success, failed, error_file_url), allowing users to download the error file, correct mistakes, and re-upload only the failed rows.
When implementing these Excel export features, I encountered significant inconveniences with the Excel processing libraries available in the TypeScript ecosystem. For instance, when applying background colours to specific rows, the surrounding rows would occasionally be coloured as well. I addressed this by iterating through individual cells within each row and applying the background colour explicitly. These accumulated frustrations led me to consider Python, which has a much more mature ecosystem for Excel manipulation libraries.
Additionally, I had recently used Python for several side projects, which eliminated any hesitation about making the switch.
Furthermore, I wanted to separate services by domain into a microservice architecture. In this context, FastAPI’s lightweight nature seemed more suitable than Nest.js, which enforces a predefined architecture that I must follow. FastAPI allows me to apply design patterns according to my specific needs. Whilst TypeScript offers lightweight alternatives such as Express.js, the combination of Excel processing requirements and other considerations made Python the more compelling choice.
I also preferred to use type hints at an appropriate level rather than enforcing strict type checking throughout the entire project. Python aligned more naturally with this requirement compared to TypeScript.
5. Authentication: AWS Cognito
The existing service had a basic JWT-based authentication and authorisation system. Although user registration functionality existed, it was not publicly exposed—I manually created users and distributed credentials. The system included login, JWT-based authentication and authorisation, and email-based password reset functionality.
During this migration, I wanted to reduce the burden of implementing user management and authentication according to industry best practices. Consequently, I opted to try AWS Cognito, an AWS managed service for identity management.
Looking at the pricing structure, Cognito offers up to 10,000 MAU (Monthly Active Users) per AWS Organisation at no cost, which far exceeds my usage requirements. This meant I could manage authentication and authorisation conveniently without incurring additional expenses.
One consideration was the potential vendor lock-in to this service. However, given that all resources were already running on AWS and the likelihood of migrating to another platform was negligible, I considered this an acceptable trade-off.
6. Database: DynamoDB
The existing RDS t4g.micro instance represented a substantial portion of the monthly costs; therefore, I needed to migrate to an alternative database service.
Again prioritising cost efficiency, I began evaluating available options. I systematically eliminated choices that required always-on compute resources, as these would incur costs regardless of traffic patterns. The most suitable option proved to be DynamoDB.
When using DynamoDB’s on-demand capacity mode, charges apply only for RRU (Read Request Units) and WRU (Write Request Units), not for uptime. This made it ideal for projects such as mine, characterised by low traffic volumes and frequent idle periods. While there are additional charges for data storage and backups, these were not burdensome given the limited data volume. Notably, the first 25 GB of data storage is always free; consequently, with minimal data, I essentially incur costs only for backup storage. Given that this configuration provides PITR (Point In Time Recovery) without additional efforts, the cost seemed justified.
One significant challenge was that all existing data had been modelled and stored using SQL, requiring complete re-modelling to fit the NoSQL paradigm. To avoid this re-modelling effort, I considered using Lambda as the primary compute resource, connecting EFS (Elastic File Storage) to Lambda, and using the file-based SQLite database on EFS. This would allow me to keep the existing SQL schema without re-modelling. However, while this approach would eliminate the data re-modelling work, it raised substantial reliability concerns compared to DynamoDB. Moreover, the requirement to manually manage redundancy and backups would actually demand more operational effort overall. Ultimately, I chose to use DynamoDB and undertake the data re-modelling and migration work.
7. Messaging: SQS, EventBridge
I needed a messaging service to enable asynchronous communication between services. I chose AWS SQS, which offers managed scaling and high availability without operational overhead. SQS provides the first 1 million requests at no cost monthly, which would significantly reduce expenses.
As I did not require the exactly-once delivery or FIFO delivery guarantees that FIFO queues provide, Standard Queues were sufficient for my needs.
For periodically collecting platform metrics, I needed to execute Lambda functions at specific intervals; EventBridge Scheduler was the natural choice for this requirement. It triggers a scheduler Lambda function periodically, which reads from DynamoDB with read-only permissions and enqueues metric collection requests to SQS.
8. Object Storage: S3
For storing service-related files, S3 was the obvious choice as AWS’s object storage service.
Object storage was needed in three scenarios:
- Storing influencer consent form PDFs for personal information compliance
- When bulk influencer registration experiences partial failures, collecting failed entries into an Excel file with error reason columns, uploading it to S3, and returning a JSON response with result statistics (
total,success,failed,error_file_url) - For asynchronous processing via API Lambda → SQS → Worker Lambda, enabling workers to access user-uploaded files (the API uploads files to S3, includes the S3 key in the message, and workers retrieve them)
For scenarios 2 and 3, files are used once and never accessed again; therefore, I configured S3 lifecycle policies to automatically delete objects after a set period.
For scenario 1, based on observed usage patterns, the data was infrequently downloaded. It is primarily stored for record-keeping purposes, and most queries verify whether an influencer has a consent form rather than actually downloading it. This verification can be accurately performed by maintaining consistency between the database table and S3, without actually querying S3. Consequently, I configured the lifecycle to transition objects to Standard IA (Infrequent Access) storage class after 30 days.
The main difference between Standard and Standard Infrequent Access storage classes is that IA offers reduced storage costs but charges for object retrieval (which Standard does not) and higher API request costs for operations such as PUT, LIST, and GET. Given that the consent form bucket experiences minimal read/write activity and primarily serves as an archive, transitioning to IA storage class made logical sense.
9. API: AWS HTTP API Gateway
To integrate and expose backend services distributed across multiple Lambda functions, I opted to use AWS API Gateway. AWS API Gateway is available in two variants: HTTP and REST. I chose HTTP primarily due to its superior cost efficiency compared to REST API.
I did not require any of the features REST API provides, such as request quotas, response caching, or API key management. The cost efficiency of HTTP API, simpler implementation compared to REST, and lower latency made it optimal for my requirements.
One limitation is that LocalStack, a service that emulates AWS services locally (which I discuss later), does not provide HTTP API Gateway in the free licence tier. I have access to a paid licence that includes this service. However, developers without such access would need to test individual backend Lambdas locally integrated with other AWS services such as DynamoDB and SQS. They would then need to deploy a development environment on actual AWS infrastructure to test API Gateway integration and verify API responses.
10. Monitoring: CloudWatch Metrics, CloudWatch Logs + SNS, X-Ray
For monitoring, I opted to use AWS-provided and managed CloudWatch rather than self-hosted solutions such as Prometheus and Grafana, which require dedicated compute resources. While CloudWatch can become expensive with substantial log volumes, high metric cardinality, or extensive custom metric usage, for this low-traffic service, I determined it would be more cost-effective than running monitoring servers continuously. Additionally, Lambda logs are automatically sent to CloudWatch by default, which provided operational convenience.
For similar reasons, I adopted AWS X-Ray for distributed tracing. One constraint is that AWS HTTP API Gateway, unlike REST API, does not support X-Ray tracing integration. Consequently, tracing starts only when the Lambda function executes. I can trace the duration of DynamoDB calls, HTTP requests, and other operations within the Lambda, but I cannot trace the complete API Gateway → Lambda flow. Nevertheless, the cost efficiency and operational simplicity of HTTP API Gateway outweighed this limitation, and I did not consider it worthwhile to switch to REST API solely for this feature. Should detailed latency analysis become necessary, I can use API Gateway’s built-in metrics such as Latency and Integration Latency for sufficient analysis.
11. LocalStack
11.1. Local AWS Emulation
As evident from the technology stack descriptions above, all infrastructure components run on AWS, and I primarily used AWS-native services rather than generic open-source alternatives such as PostgreSQL. This made it challenging to simulate and test infrastructure components locally. With generic open-source services, I could run them as containers and test inter-service interactions; however, testing DynamoDB, SQS, and similar managed services locally was not feasible through conventional means.
While I could use mocks or stubs instead of directly communicating with DynamoDB, SQS, and other services, then perform final verification in a development environment deployed on actual AWS infrastructure, I wanted robust feedback during local development.
To accomplish this, I adopted LocalStack, which emulates AWS services within local containers. This enabled me to make actual calls to DynamoDB and SQS, verifying that data was correctly written and retrievable.
However, LocalStack is fundamentally open source with a free licence, though certain services are unavailable in the free tier. The licensing documentation shows which services are available in each licence tier. While basic usage is well supported, if I needed to test specific services locally without paid licence, I would need to evaluate whether they are available in the free licence or whether getting a licence is worthwhile.
11.2. Limitations and Workarounds
Since services are emulated rather than running in an actual AWS environment, certain AWS APIs may be implemented late. During development, I encountered an issue where upgrading Terraform version caused resources to fail creation in LocalStack. This occurred because an API used by the latest Terraform version to verify state consistency between the backend and actual infrastructure had not yet been implemented in LocalStack.
I resolved this by downgrading Terraform; however, it is important to be aware of such potential issues.
Additionally, since LocalStack runs locally, computing resources are not as abundant as in AWS, which can cause performance degradation in certain scenarios. For instance, when testing the complete process flow from API Lambda → SQS → Worker Lambda to verify a feature, I observed significantly slower processing when many messages accumulated in SQS simultaneously. In actual AWS, multiple Lambda instances execute concurrently to process messages quickly. However, due to local emulation characteristics, LocalStack presumably could not run as many Lambda instances concurrently as actual AWS does.
Nevertheless, for testing purposes, I could simply reduce the message volume, and to evaluate how many messages can be processed at a given scale, I could run tests in the actual AWS environment; consequently, this was not a significant issue.
12. IaC: Terraform
12.1. Why I Switched from AWS CDK
Previously, I used AWS CDK (TypeScript) to manage infrastructure. At the time, lacking experience with IaC tools, I chose AWS CDK because I could manage infrastructure with a familiar programming language rather than learning a new domain-specific language or framework.
AWS CDK fundamentally operates by defining infrastructure in code, converting it to an AWS CloudFormation template, and then executing it. This characteristic means it follows CloudFormation’s default behaviour. I had accumulated some dissatisfaction with AWS CDK, and given that Terraform is the most widely adopted IaC tool with abundant community resources and particularly well-suited for code generation with AI assistance (due to the large corpus of existing Terraform code), I opted to try Terraform.
My primary frustration with AWS CDK was its default behaviour of attempting changes → rolling back entirely upon failure. Theoretically, automatic rollback upon infrastructure change failures represents the safest approach; therefore, I initially thought it was good.
However, I once encountered an issue where an ECS service would not transition to Active status during CDK deployment. It was difficult to identify the exact problem. The process of waiting extensively for the service to become active, followed by rolling back all resources when it failed, consumed considerable time and prolonged troubleshooting. Although this problem was ultimately due to my own skill issues, the resolution process was not smooth. The long deployment and rollback times were inconvenient, which motivated me to try Terraform.
12.2. Development Experience with Terraform
With Terraform, when I write Terraform configuration and apply it, Terraform calculates the required changes and calls AWS APIs directly. Should a failure occur mid-deployment, there is no built-in functionality to automatically roll back all previous actions. This could be seen as a limitation compared to AWS CDK. However, regardless of lacking this feature, infrastructure application and rollback subjectively felt faster with Terraform than with AWS CDK. Of course, Terraform-managed resources in this project are mostly serverless components such as Lambda and SQS, whereas AWS CDK managed resources such as ECS and ALB, which require waiting until they achieve Active or Healthy status, contributing to time differences. Nevertheless, my subjective impression was that the overall experience was much more pleasant.
When problems occurred mid-deployment, the approach of not rolling back but instead identifying the issue, fixing it, and reapplying changes felt more efficient.
Whilst automatic rollback is not built-in, if such a situation arose, I could manually revert code with Git and reapply, provided I manage source code with Git and Terraform state remains intact.
Having used both tools, I found that for managing infrastructure code, Terraform’s declarative syntax felt more intuitive than incorporating the full complexity of a programming language’s syntax. The programming features required when defining infrastructure are primarily basic conditional logic, iteration, and variable references, and Terraform provides these capabilities sufficiently. Code reuse can be accomplished through Terraform modules; consequently, there is no need to bring in the full complexity of programming language syntax.
Using generative AI for infrastructure code proved highly satisfactory. Despite being relatively unfamiliar with Terraform, I could describe desired attributes or configurations in natural language, direct Claude Code to generate the infrastructure definition, review the generated code, and apply it using terraform plan and apply. This workflow was generally satisfactory and helped me adapt to Terraform relatively easily. However, occasionally the AI used deprecated options from earlier versions or could not configure exactly what I needed; in such cases, I consulted the official Terraform documentation for available options per resource and made necessary corrections.
12.3. Managing Multi-Environment State
One challenge with Terraform was separating state by environment. I needed separate state management for local, development, and production environments. Initially, I tried using the Terraform workspace feature but encountered difficulties. Ultimately, I defined infrastructure as reusable modules and separated directories by environment, with each environment specifying its own backend configuration for state storage. I’ll cover this approach in detail in a future post.
13. React + Vite
For the frontend, I reused existing code while modifying API calls to align with the new API structure. Considering Lambda and API Gateway timeout constraints, I converted most operations from synchronous to asynchronous patterns, updating the user experience accordingly.
For authentication and authorisation, I removed the existing custom UI and integrated with AWS Cognito. I used AWS Amplify for this integration, which is well integrated with AWS Cognito and automatically manages token expiration verification, token refresh using refresh tokens, login processes using the SRP protocol, and other authentication concerns through well-designed abstractions. Given that UI consistency was not critical for this project, as it was an internal tool, I could use Amplify’s pre-built Authenticator component, simply modifying input field labels and placeholders to Korean, which significantly accelerated development.
14. Electron
For the desktop application needed to collect platform metrics (discussed in Part 1), I chose to continue using the existing Electron-based application.
14.1. Integration with AWS Cognito
While reusing the application, I needed to modify it to accommodate the revised API structure and migrate authentication and authorisation to AWS Cognito, similar to the frontend.
Electron embeds Chromium to use the browser as a rendering engine. This characteristic enables seamless cross-platform support; however, for security purposes and to ensure each rendering process operates independently, it maintains a separated architecture between renderer and main processes. Consequently, APIs for network requests, filesystem access, and similar operations can only run in the main process, while the renderer process exclusively handles UI presentation.
Due to this architectural constraint, I could not simply import and use AWS Amplify components as I had in the frontend. This is because Amplify components make network requests to communicate with AWS Cognito directly within the component; however, since these components run in the renderer process, network requests are not allowed. Therefore, in Electron, I implemented authentication at the main process level using the aws-cognito SDK directly.
14.2. Development Challenges
I have consistently used Electron when needing simple desktop GUI applications. While I have used it for small-scale applications, its inherent separation between main and renderer processes, and the resulting need to always communicate via IPC (Inter-Process Communication), has consistently felt unnecessarily complex, resulting in suboptimal development experiences.
Additional difficulties arise when building browser automation applications. Electron incorporates Chromium natively, and browser automation libraries such as Playwright and Puppeteer also require Chromium or alternative browsers as dependencies. Due to conflicts with Electron’s embedded Chromium, issues occurred during package building. Ultimately, I had to use libraries such as playwright-core that remove browser dependencies and provide only browser control APIs, then locate and launch the Chrome installation path on the user’s system. This workaround felt inelegant and did not provide a satisfactory development experience.
14.3. Considering Alternatives
Due to these inconveniences, I considered using Python with PyQt, and tried it for several side projects. While the absence of IPC complexity and the ability to handle network requests and filesystem access directly was advantageous, and bundling Chromium was feasible, I have mostly used React for UI development and am particularly accustomed to declarative UI paradigms. Most UI libraries such as PyQt use an imperative approach, which I found unsatisfying.
Ultimately, while Electron provides a satisfactory experience for UI development, the development experience for core logic is not optimal due to the need to write additional code for renderer-main process communication via IPC. Additional complications arise when bundling with other packages that require Chromium as a dependency. Given that this project was already implemented in Electron, there was no compelling reason to migrate to an alternative framework or library; consequently, I continued using it. However, should I need to develop similar applications in future, I intend to research and try alternative available technologies.
15. Playwright
I use Playwright within the desktop application to control the browser when collecting metrics. While primarily used for end-to-end testing in frontend development, it is equally excellent for web automation purposes.
Previously, I used Puppeteer, an open-source browser automation tool maintained by the Chrome Browser Automation Team. Theoretically, both Playwright and Puppeteer can implement identical functionality; however, in terms of developer experience, Playwright proved overwhelmingly superior. Puppeteer feels like directly using browser APIs, requiring substantial effort not just for core functionality but for understanding and coordinating APIs. Conversely, Playwright provides APIs abstracted in a much more developer-friendly manner, allowing greater focus on core functionality.
For instance, when selecting specific DOM elements, Puppeteer only provides page.$ and page.$$, which use the same syntax as document.querySelector and document.querySelectorAll. However, Playwright provides APIs such as getByRole, getByText, and getByLabelText, similar to React Testing Library, enabling code that mimics how humans interact with browsers.
Additionally, a tedious yet essential process in browser automation is writing Locators that precisely target desired DOM elements. The Codegen feature can automate this by opening a browser on the actual website, allowing me to click desired elements and generating locators automatically.
While Codegen exists, it is primarily designed for writing end-to-end test code, making it somewhat inconvenient for other purposes. Recently, with Playwright MCP enabling integration with AI agents, I can describe desired elements to the AI and receive much more accurate initial code drafts than before, significantly simplifying usage.
Personally, this is my preferred tool without hesitation when browser automation is needed. The convenient APIs for selecting diverse locators and the ability to filter selected locators represent game-changing improvements, and I intend to continue using it.
16. CI/CD: Local Bash Scripts + GitHub Actions
16.1. The Local CI Philosophy
I did not implement a fully remote CI/CD pipeline. However, this was an intentional decision.
Shortly before starting this project, I read DHH’s post on moving CI back to developer machines. The core argument is straightforward: modern development machines possess sufficient computing power, whilst CI servers often lack comparable performance or require significant cost to achieve it.
Rather than investing effort into configuring, operating, and maintaining complex remote CI infrastructure, the philosophy advocates running tests locally, verifying they pass, and then proceeding with pull request merges or deployments.
Naturally, like all programming principles and methodologies, this approach is not universally effective. DHH’s post explicitly acknowledges this limitation.
16.2. Why Local CI Suited This Project
For this project, the local CI approach proved ideal for several reasons:
Solo Development Context: As the sole developer, configuring my local environment properly allowed me to execute the entire process more quickly and conveniently than setting up and maintaining remote CI infrastructure.
Enforcement Mechanisms Unnecessary: Remote CI typically enforces quality gates—preventing pull request merges when tests fail. For a solo project, such enforcement provides no value. I could simply ensure tests passed before deploying. Interestingly, DHH mentioned that even when working in teams, he trusts team members to possess the professionalism and responsibility to run local CI and verify results before requesting pull request approvals. He reported no issues with this approach at his company.
16.3. Implementation Approach
I adopted a hybrid strategy, distributing responsibilities between remote and local execution:
Remote Execution (GitHub Actions):
- Frontend deployment: Build processes, S3 upload, CloudFront cache invalidation
- Desktop application: Windows builds, S3 distribution
Local Execution:
- All testing: Whether running against LocalStack-emulated AWS services or development environment infrastructure, test execution occurs locally
- Backend deployment: Lambda function updates, Docker image builds, ECR pushes
- Infra deployment: Apply Terraform to AWS environment
Automation Strategy:
All testing and deployment processes are encapsulated in single-command executions using Bash scripts and Makefiles:
- Testing Script: Executes unit, integration, and end-to-end tests
- Deployment Script: Builds Docker images, pushes to ECR, and updates Lambda functions. Given the monorepo structure (multiple services in a single repository), it accepts a service name parameter to determine which service to deploy
- Terraform Script: Applies infrastructure definitions, then synchronises Terraform outputs to environment files (
.env.local,.env.dev) for subsequent test execution
All scripts accept an environment parameter (local or dev) to target the appropriate environment.
16.4. Development Experience
The hybrid local-remote CI/CD approach proved highly satisfactory:
Reduced Complexity: CI infrastructure setup complexity decreased substantially.
Performance: Execution speed met expectations on both my M1 MacBook (used initially) and current Intel Core Ultra 9 185H Linux machine. Hardware performance never became a bottleneck during the CI/CD process.
Developer Experience: The ability to immediately access logs and error messages on my local machine when CI/CD issues occurred made debugging significantly more convenient.
Iteration Speed: The flexibility to execute tests and deployments as frequently as needed, without remote infrastructure constraints, proved valuable.
16.5. Applicability and Trade-offs
This approach is unsuitable for large teams requiring formal quality gates and enforcement mechanisms. However, for solo developers or small teams with sufficient professional discipline to consistently follow processes, it represents a viable alternative worth considering.
The cost savings, reduced operational overhead, and improved debugging experience aligned well with this project’s constraints and priorities.
17. Next in the Series
Part 4: Data Modelling for DynamoDB will cover the RDS to DynamoDB migration:
- The Single-Table Design Decision: Why I initially chose single-table design
- The Pivot to Multi-Table: Why I changed my approach mid-migration
- Access Patterns: How actual query patterns influenced the final design
- Migration Strategy: Transforming SQL schemas to NoSQL data models
Series Navigation
- Part 1: The Initial Server-Based Architecture
- Part 2: The Cost Crisis and Path to Change
- Part 3: Technology Choices and Their Rationale (Current)